The operational excellence pillar ensures that your systems are running smoothly and that you can respond quickly to issues that pop up. This includes factors such as change management and monitoring and logging your deployments, ensuring that when an incident does occur, you can quickly and appropriately respond to it before it becomes a larger issue.
Now, we will look at a case study of a Multi-AZ active-active production environment. A Multi-AZ active-active production environment refers to a setup where resources and workloads are distributed across multiple availability zones (AZs) and all of these zones are actively handling traffic simultaneously. This configuration ensures high availability, fault tolerance, and seamless failover by allowing operations to continue unaffected even if one zone experiences issues, thereby maximizing uptime and resilience for applications and services.
A case study of a Multi-AZ active-active production environment
As mentioned many times throughout the book, optimization is a key feature of IoT deployments. We want to ensure that we use the resources that are most appropriate for the task. However, reliability for our services is just as important as that, given that we want to ensure that our deployment can keep functioning no matter what happens. In the following figure, we can see one such architecture that is designed for this:
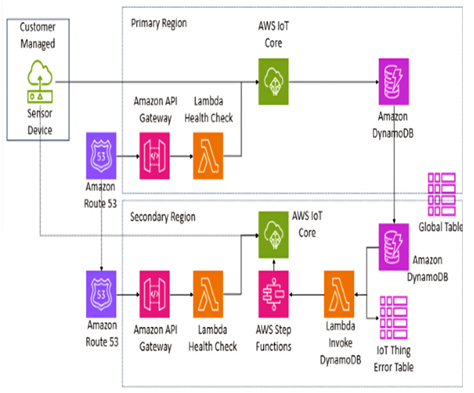
Figure 7.6 – Example of a Multi-AZ active-active production deployment on AWS
This architecture has many components, but as can be seen, it is designed for fault tolerance. First, we have two regions where our deployment is based: the primary region and the secondary region. These regions, parts of AWS’s global infrastructure, are separate geographic areas that enhance reliability; if the primary region fails, the secondary region takes over to maintain service continuity and traffic will flow just as accordingly through there. Additionally, we use AWS Route 53, a scalable and highly available domain name system (DNS) web service, which directs user traffic to the infrastructure running in AWS. We can also see that we have Route 53 endpoints that perform a health check through Lambda instances, which continuously check if the services are down and take action if so. We also have our storage located within DynamoDB, a fast and flexible NoSQL database service, which is where the data that comes from the sensor device into AWS IoT Core is stored, both in terms of shadow updates and registry events. The DynamoDB table also has global table replication enabled, enabling it to continuously replicate its contents so that if one is down, the other would not be affected.
This type of deployment creates a powerful way of ensuring that the workloads will continue to operate even if one of the parts of the system were to go down. We will see more of these best practices in the next chapter, as we look to include data analytics services within the big picture of the IoT networks that we are trying to architect on AWS.
With a foundational understanding of the important AWS services and how they contribute to the IoT ecosystem, we can look at doing a practical exercise that puts our new knowledge and skills into practice.
Leave a Reply